Streaming CSV inside a ZIP File with Go Channel
So I have a pretty tough use case where I need to load 2GB of CSV files into a database and somehow manages it to be done in a container where it limit RAM usage into less than 200 MB.
First things first, how do you even load the CSV file? 2GB CSV file won’t fit into 200 MB of RAM. I wish there’s easy “PHP” way where file uploads is the language job. But hell no, since we’re running our backend in a container we’re using GCP for file uploads. Normally, when our backend need that file via GCP API, we download that file entirely and put it in the memory.
import "cloud.google.com/go/storage"
type GcpStorage struct {
client *storage.Client
}
func (s *GcpStorage) ReadObject(bucket string, object string) ([]byte, error) {
rc, err := s.client.Bucket(bucket).Object(object).NewReader(context.Background())
if err != nil {
return nil, err
}
defer rc.Close()
// we read all of them (note: will crash with 2GB of CSV!)
return io.ReadAll(rc)
}
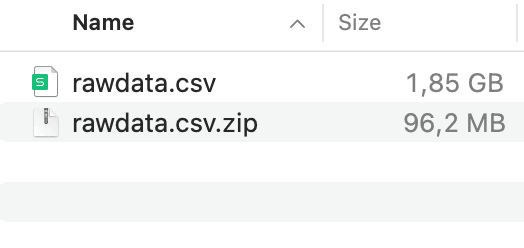
We could simply replace the io.ReadAll with a loop that reads CSV line-by-line to avoid reading all the contents of the file and crashing the backend. But do you know what else that I hate? The fact that user have to literally upload the 2GB worth of text file. Why not compressing it beforehand? It significantly saves the network bandwidth and S3 storage. A real test shows when it get compressed, the size shrunk 20x times!

When I started to code it, I thought stream process should look like this:
Open S3 stream from bucket path
Open zip stream from S3 stream
Open CSV stream from a CSV file inside a Zip stream
I came into a problem at step 2:
Zip doesn’t support streaming bytes. It must be able to seek at specific byte position. Source: https://stackoverflow.com/a/16947430
The GCS API (that we’re using) may support seed/randomized byte position reading via NewRangeReader, an S3 Read that capable of reading at specific offset bytes. But Go Zip package can’t use this to its advantage so you’re stuck with classic
NewReader— but you just can’t clever out the Go Interface.
But in the grand scheme of things, trying to seek bytes (ie. randomized read bytes) is a terrible idea for over-a-network reading (too many round trips!) so it’s better to download the whole zip file into the memory. The new streaming approach is this:
Open S3 stream from bucket path
Read all file bytes from S3 stream
Open zip stream from file bytes
Open CSV stream from a CSV file inside a Zip stream
At step 2 we’re allocating 100 MB worth of zipped file, which is fine because it’s still lower than our RAM limit. Here’s the code looks like:
func (s *GcpStorage) Read(bucket string, object string) (io.ReadCloser, error) {
rc, err := s.client.Bucket(bucket).Object(object).NewReader(context.Background())
if err != nil {
return nil, err
}
return io.ReadCloser(rc), nil
}
func (s *GcpStorage) ReadFileCsvInZipStream(reader io.ReadCloser) (*zip.File, error) {
defer reader.Close()
// this reads the whole zip file! (~100 MB allocation)
fileBytes, err := io.ReadAll(reader)
if err != nil {
return nil, err
}
// these readers don't need Close() since the data lives on memory
byteReader := bytes.NewReader(fileBytes)
zipReader, err := zip.NewReader(byteReader, int64(len(fileBytes)))
if err != nil {
return nil, err
}
for _, f := range zipReader.File {
if filepath.Ext(f.Name) == ".csv" {
f.Open()
return f, nil
}
}
return nil, errors.New("CSV File not found")
}
The *zip.File contains func (f *zip.File) Open() (io.ReadCloser, error) which returning a file stream that we can put into a function that can process a streamed CSV file.
For the CSV streaming process, we want to “batch” the process. It’s like if we have read 100 lines from CSV, we execute a single INSERT statement containing 100 row of data into our DB.
It maybe easy to do the batching via single loop of strings.Split(s, "\n") and say if i % 100 == 0 then do the insertion. However, we won’t reinvent the wheel writing CSV parser ourself. We’ll use https://github.com/gocarina/gocsv and they have a specific function to parse a streamed CSV file:
// UnmarshalToChan parses the CSV from the reader and send each value in the chan c.
// The channel must have a concrete type.
func UnmarshalToChan(in io.Reader, c interface{}) error {
// ....
}
Whoa, wait! a channel?! Why would someone use that complicated mess???
You’re not alone. I’ve been coding Go for three years and i’ve never use something like that complicated professionally. But I kept go on and later it made so much sense to use channels because unlike Javascript, you would want to pass channels rather than functions.
Let’s say I want to tell our CSV parser to read into this struct:
// A simulation data. Name, Metadata, Properties are from CSV. Anything else is automated.
type SimulationData struct {
ID uuid.UUID `gorm:"type:uuid;column:id;primaryKey" json:"id"`
Name string `gorm:"type:text;column:name" json:"name" csv:"Name"`
Metadata string `gorm:"type:text;column:metadata" json:"metadata" csv:"Metadata"`
Properties string `gorm:"type:text;column:properties" json:"properties" csv:"Properties"`
NthIndex int `gorm:"type:int;column:nth_index" json:"nth_index"`
}
We read the CSV this way, where reader is from Open() of a *zip.File, and payloadChan is the channel where we will process insertion into the database.
func ReadCsvStreamed(reader io.ReadCloser, payloadChan chan []SimulationData) error {
defer reader.Close()
var csvRowChan = make(chan SimulationData)
// this function runs on separate thread
go func() {
// we close it here since we send the channel data from here
defer close(payloadChan)
rows := make([]SimulationData, 0)
index := 0
for row := range csvRowChan {
input := row
input.ID = uuid.New()
input.NthIndex = index
index += 1
rows = append(rows, input)
// when current batch is over 100
if len(rows) >= 100 {
payloadChan <- rows
rows = make([]SimulationData, 0)
}
}
// send remaining data if any
if len(rows) > 0 {
payloadChan <- rows
}
}()
// csvRowChan is closed inside this function
if err := gocsv.UnmarshalToChan(reader, csvRowChan); err != nil {
return err
}
return nil
}
All legos bricks needed are defined. Now, we stack it together:
func Handler(storage *GcpStorage, db *gorm.DB, wg *sync.WaitGroup, filename string) (err error) {
zipReader, err := storage.Read("mybucket", filename)
if err != nil {
return
}
// zipReader is closed here
zipHandle, err := storage.ReadFileCsvInZipStream(zipReader)
if err != nil {
return
}
fileReader, err := zipHandle.Open()
if err != nil {
return
}
pchan := make(chan []SimulationData)
wg.Add(1)
go func() {
for p := range pchan {
if err := db.Create(p).Error; err != nil {
fmt.Printf("%+v", err)
}
}
wg.Done()
}()
// pChan and fileReader is closed here
err = ReadCsvStreamed(fileReader, pchan)
return
}
If you look closely, there are three threads in this process:
The main thread, which finished when
Handler()finished reading the CSVThe thread inside
ReadCsvStreamed()which receiving the data from CSV and collect it into another thread in the form of row batchesThe
go func()thread inside the main thread, which process the batched rows into gorm database withdb.Create.
You may wonder what’s wg sync.WaitGroup for? It is used if you want to make sure your app waits for all asynchronous tasks to be completed before shutting down.
For completeness, here’s the simple main function:
func main() {
storage := GcpStorage{}
db := gorm.DB{}
wg := sync.WaitGroup{}
// init storage and db from envar
// ....
// normally you place the handler inside HTTP function
// but for brevity we call this directly
if err := Handler(&storage, &db, &wg, "myfile.csv.zip"); err != nil {
panic(err)
}
fmt.Println("All CSV data is parsed")
wg.Wait()
fmt.Println("All CSV data is saved")
}
Now you know how to handle go routines and channel and what it is used for and why it needed! Imagine if we had to do this in the Javascript way (i.e. passing functions instead of channel) it’s gonna be terrible (you may have to deal with hardcoded type / interface{} conversions a lot) and our code won’t gain from multithreading!
Full code: https://gist.github.com/willnode/75a96840ff33ada3f2aa3db3d28cde07